Discovering Blueprint VM (Part 2)
In this article, I’m going to explain how Blueprints work behind the scenes again, but this time I’ll be a little bit more technical.
In previous article we mentioned common myths, how graph system works, what kind of interpreter Blueprints has and how Blueprints are translated into bytecode. In this second part of the article, we’re going to ignore the beginners and high-level systems, but focus on questions like:
- “why custom thunks are pain to work with?”
- “could Blueprints be more faster?”
- “what are the compilation steps of blueprint graph?”
Enjoy!
Bytecode representation of the graph
So where the hell bytecode is stored anyway? Or even, what the hell is a bytecode exactly???
These are easy questions to answer!
Each Custom Event Node and each Function in your blueprint graph (including interfaces) holds the information of which nodes connected to it in order. Those two specific nodes are “entry points” for the bytecode execution because execution logic only begins with them by default. And each entry point is represented by UFunction class - which stored in UClass with the name of FunctionMap - and each UFunction* stored in the class contains the bytecode data for it’s execution.
So each node that we can call as entry point holds its own bytecode data. Blueprint compiler evaluates entry points and serializes bytecode into them. You can access the generated bytecode from UFunction::Script, which is a public variable.
A bytecode is basically an enum. Nothing more, nothing less. It was called as p-code (portable code) earlier, but after a specific age in programming history since it’s size can be fit into a single byte, programmers started to call p-code’s as bytecodes instead.
In Unreal Engine, the enum represents the generated bytecode is EExprToken. And UFunction::Script is an array of uint8s, which points to members of EExprToken.
Ok - nice to know. But how the hell a “byte” can represent all the info a node contains?
Nice question. A bytecode only describes a single “instruction” that is going to happen. During blueprint compilation, a class named FScriptBuilderBase is constructed and UFunctions (that represents the entry point currently being compiled) Script property being passed into the it. Then FScriptBuilderBase starts to write bytecode into Script for each compiled blueprint statement.
Blueprint statements are generated from node graph, heavily relying on the pins that your nodes provide to the blueprint compiler. They contain the information of what is connected to the pins, literal values, default values, which native/blueprint function the node calls when it’s executed, and other data structures to make blueprint compilation with various hacks. The struct represents a compiled statement is the FBlueprintCompiledStatement.
Statements cause multiple bytecodes to be written into FScriptBuilderBase. At this point, the serialization process boils down into the most evil and scary file, the "UObject/ScriptSerialization.h" (it’s saving/loading (both, FArchive style) inline data in an array of bytes). This file is pretty much a tech debt from Unreal Engine 3 and probably predates C++11. Entire file more or less is about putting inline constants into bytecode - it just has extra handling for FText translations, pointers, etc.
But… That’s just the serialization part. How a virtual machine works and what bytecode is still same - even though many hacks and weird stuff happening to compile a node-based graph for an interpreter.
Each statement generates similar instruction to this:
- Take this specific value called X
- Copy it, and set value of Y to X
- Check if X is true, and if it’s not, jump to location Y
- Get this memory address X, initialize it as Y, copy it to Z
etc.
Alright, we need more information about those implicit sentences that explains generated instructions.
This won’t cut and doesnt explain much. Let’s dive deeper.
We already know bytecode is stored in an array in UFunction as TArray<uint8>.
The thing is, before compilation, compiler also sorts your sphagetti graph to execute them in order, linearly. Now the question would/should be “But my sphagetti graph is not linear, I hate myself and my colleagues so I create cyclic logic between my nodes and they loop until I break out of the recursion?!”
You’re right! Blueprints let you abuse the potentials and ignore the correct programming patterns. But from compiler’s perspective, tou should imagine like each node you put to graph has an index. And a scripting language VM basically just jumps to a specific index in the bytecode array to another. And it can totally do this dynamically, without requiring a pre-defined data to be set for it.
For example, lets say you have a node like this:
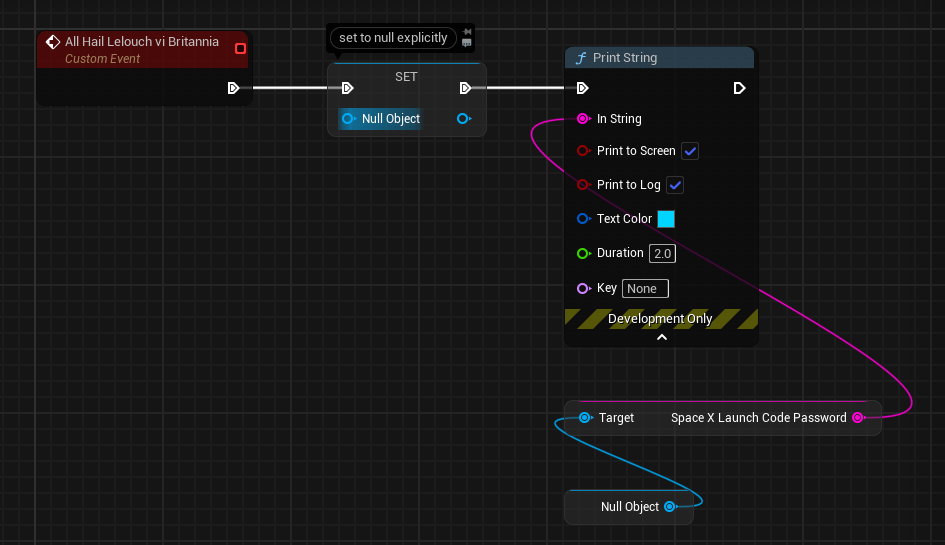
Before “Null Object” to be accessed, Blueprint VM must check if it’s pointing to a valid object or not. Because unlike C++, it doesn’t let you crash your project intentionally and lets you continue executing your logic. But on the other hand, it also must provide a value for the In String pin.
Basically, in this case, whenever Blueprint VM accesses to an object value, it runs a fail-safe logic to not crash (see DEFINE_FUNCTION(UObject::execLetObj) and DEFINE_FUNCTION(UObject::execSelf)) - but if it understands the object points to a null pointer, it doesn’t provide anything to the node trying to get a value from it but jumps to next instruction directly.
Before running the Print String node, the SpaceX Launch Code Password variable wasn’t initialized yet, so it only contains what a string variable can contain by default - which is an empty string.
Since Blueprint VM couldn’t access valid object, it won’t receive the value from the Null Object and when Blueprint VM jumps to the bytecode that is suppose to set In String pin of the Print String node, SpaceX Launch Code Password will only be able to provide it’s default value: "". An empty string.
Ok, but.. can you come to the point?
The scenario we went through above explains Blueprint VM is able to jump to n more instructions back/forth from the current instruction logic. Because, in the end, everything is a TArray<uint8> (see FFrame::Step(UObject* Context, RESULT_DECL) - the (GNatives[B])(Context,*this,RESULT_PARAM) is a fancy representation with some magic of the bytecode array).
Basically every custom thunk, bytecode, or any other data or instruction Blueprint compiler generates, just tries to manipulate the direction of the Blueprint VM’s jumps.
This is basically nothing different than how a LIFO (Last in First Out) data structure works. But just a very fancy version of it.
So the instruction examples like “take X, add to Y, jump to Z” are just basically operations happening like this.
So what makes Blueprints slow exactly?
I will shamelessly admit I have no idea about this specific topic. :sweat_smile:
Mostly because my programming knowledge is limited (and developed) with Unreal Engine only. I need to know how other scripting languages work first - like possibly GDScript (if it’s even faster?) so I can compare two.
But of course, there are things I can add. From most obvious one to possibly less known ones:
- Blueprints is not a register-based language but a stack based one, which makes it naturally slow.
- There is no top-down optimizer, nor a possibility for it to exist.
- Output params are copied everytime magnificently :sparkles: and there is no way to avoid it - except if it’s an
Array Get (ref)node. - Almost more than half of the default nodes expand to multiple nodes during compilation and single node generates way more than instructions than how it looks in the graph. (specifically async actions cause too many expansions)
- Each time a node is executed output params must be looped and initialized to their values
- VM back end is a branchy horror and full of Unreal-specific implementations
- UnrealScript (UE3) was also very slow.
- VM dispatches function pointers instead of implementing main interpreter loop in a switch/case statement like traditional VMs.
- The booleans added to blueprint graph (not the ones derive from a native class) are packed together as bitfields, and to assign booleans VM sacrifices runtime performance for such an unnecessary memory optimization. (see
DEFINE_FUNCTION(UObject::execLetBool))
There are.. some sort of constant folding optimization happens with InlineGeneratedValue logic - which makes Math Expressions run faster, but it’s very limited. Also there is a fast-call optimization exist which is described as Call Math in the backend but it happens for non-math related nodes too.
That was all for this article. I hope it was useful! Please share to spread the knowledge!